
Quotes from DevOps Handbook
The DevOps Handbook: How to create world-class agility, reliability and security in technology organizations is the follow-on book to The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win. I had collected my favorite quotes from the Phoenix project earlier. I finally managed to get the DevOps handbook and here’s my collection of favorite thoughts from the book.

DevOps Myths
- DevOps is only for startups
- DevOps replaces Agile
- DevOps is incompatible with ITIL
- DevOps is incompatible with Information Security and Compliance
- DevOps means eliminating IT Operations, or “NoOps”
- DevOps is just “Infrastructure as Code”
- DevOps is only for open source software
DevOps Aha!
..DevOps is a manifestation of creating dynamic, learning organizations that continually reinforce high-trust cultural norms.
DevOps is the outcome of applying the most trusted principles from the domains of physical manufacturing and leadership to the IT value stream.
Technical Debt
..describes how decisions we make lead to problems that get increasingly more difficult to fix over time, continually reducing our available options in the future.
Problem with traditional Dev & Ops Structures
Talking about the discussion in the book, The Goal about conflict between traditional organizational goals and metrics,
the core, chronic effect - when organization measurements and incentives across different silos prevent the achievement of global organizational goals.
Downward spiral
.. the systems most prone to failure are our most important and at the epicenter of our most urgent changes.
Why is this important?
..every IT organization has two opposing goals, and second, every company is a technology company, whether they know or not.
There is a discussion of *dark releases* and *feature flags*. Here’s a very well written description by Martin Fowler: Feature toggles
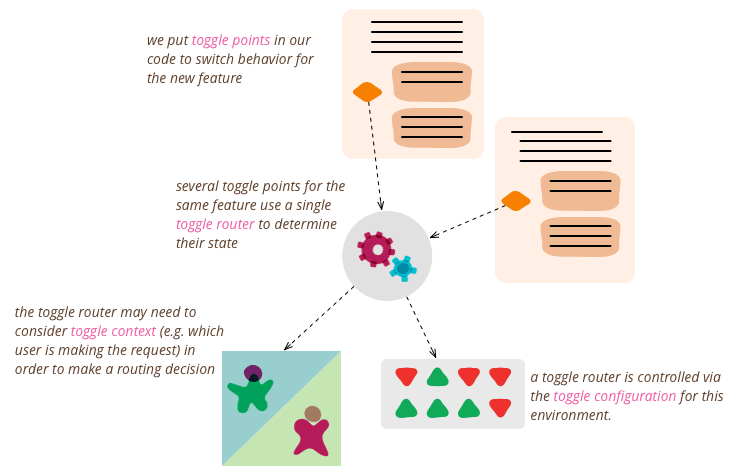
Where is DevOps impact seen?
This list is based on work done for Puppet Labs - State of DevOps report.
- Throughput metrics
- Code change and code deployments (thirty times more frequent)
- Code and change deployment lead time (two hundred times faster)
- Reliability metrics
- Production deployments (sixty times higher change success rate)
- Mean time to restore services (168 times faster)
- Organizational performance metrics
- Productivity, market share and profitability goals (two times more likely to exceed)
- Market capitalization growth (50% higher over three years)
Technology Value Stream
.. is defined as the process required to convert a business hypothesis into a technology enabled service that delivers value to the customer.
My paraphrasing:
Value stream starts when the any engineer checks
in a change (could be design, user story) and ends with this change
is successfully running in production and providing value
to customer and generating feedback and telemetry.
Why is the focus on automation?
Design and development is akin to Lean Product Development and is highly variable and highly uncertain, often requiring high degrees of creativity and work that may never be performed again, resulting in high variability of process time. In contrast, the second phase of work which includes Testing and Operations is akin to Lean Manufacturing. It requires creativity and expertise, and strives to be predictable and mechanistic, with the goal of achieving work outputs with minimized variability.
End goal:
Have testing and operations simultaneously with design and development to enable fast flow of work.
Concept of Lead Time
|<--------------- Lead Time ---------------->|
|=======================|====================|
Ticket Work Work
Created Started Completed
|<-- Process Time -->|
When we have long deployment lead times, heroics are required at almost every stage of the value stream.
The Three Ways
Taken from the blog by Gene Kim titled The Three Ways: The Principles Underpinning DevOps
First Way - Fast Flow
- First Way: The First Way requires the fast and smooth flow of work from Development to Operations, to deliver value to customers quickly. We optimize for this global goal instead of local goals, such as Development feature completion rates, test find/fix rations, or Ops availably measures.
Stop starting. Start finishing. - David J. Anderson.
Issue with hand-offs With enough handoffs, the work can completely loose the context of the problem being solved or the organizational goal being supported.
5 Focusing steps - Dr Goldratt

- identify the system’s constraint
- decide how to explot the system’s contraint
- subordinate everything else to the above decisions
- elevate the sytem’s constraint
- if in previous steps a constraint has been broken, go back to step one, but do not allow inertia to cause a system constraint.
DevOps Transformation - Focus Areas
- Environment creation
- Code deployment
- Test setup and run
- Overly tight architecture
I am paraphrasing here The goal of fast flow is to make any kind of waste and hardships - anything that requires heroics is made visible and to systematically alleviate or eliminate the burden. Types of waste that lead to heroics are:
- partially done work (sitting in QA, waiting for deployment - stuck WIP)
- extra processes (eg Documenting steps to document - I guess this is where CMM models failed)
- extra features (adding more things than a minimum viable product {MVP})
- task switching
- waiting
- motion (lack of co-located colleagues, hand-offs, KTs)
- defects
- nonstandard or manual work
Second way - Principles of Feedback
.. Second way describes the principles that enable the fast and constant feedback from right to left at all stages of value stream.
According to Dr Spear, the goal of swarming is to contain problems before they have a chance to spread, and to diagnose and treat the problem so that it cannot recur.
When automated build is used and a test fails, the entire pipeline fails - and that is acceptable. Here's the reason.
Preventing the introduction of new work enables continuous integration and deployment, which is a single piece of flow in the technology value stream. All changes that pass our continuous build and integration tests are automatically deployed into production, and any changes that cause any tests to fail trigger our Andon cord and are swarmed until resolved.
Biggest differentiator in devOps compared to traditional software life-cycle? In the technology value stream, we optimize for downstream work centers by designing for operations, where operational non-functional requirements (e.g., architecture, performance, reliability, stability, testability, configurability, and security) are prioritized as highly as user features.
Preventing the introduction of new work enables continuous integration and deployment, which is
Third way - Continual learning and Experimentation
.. the Third Way focuses on creating a culture of continual learning and experimentation. These are the principles that enable constant creation of individual knowledge, which is then turned into team and organizational knowledge.
How?
We improve daily work by explicitly reserving time to pay down technical debt, fix defects, and refactor and improve problematic areas of our code and environments.
Selecting the correct Value Stream
Greenfield / brownfield do not matter - as long as the application is architected (or re-architected) for testability and deployability.
Although systems of engagement are more easy to adopt to devOps, it is the systems of record that can form a bottleneck. So everything in the org has to move to devOps going against the bimodal IT design.
Understanding work
Next step in value stream is:
..what work is performed and by whom, and what steps can we take to improve flow
Typical teams involved in value stream mapping:
- Product owners
- Development
- QA
- Operations
- InfoSec
- Release Managers
- Technology executive or value stream manager
Managing Technical Debt and Non-functional requirements Invest around 20% of all dev and ops time on Non-functional requirements. This is the only way to pay down technical debt.
Use tools to reinforce behavior
Tools should be designed such that dev and Ops use the same systems to create a queue of shared work. It can show a unified backlog. This can help in prioritizing work that delivers highest value to the organization.
Designing Organizational Structure
Dr. Melvin Conway - Conway’s Law:
“organizations which design systems…are constrained to produce designs which are copies of the communication structures of these organizations….The larger an organization is, the less flexibility it has and the more pronounced the phenomenon.”
Simplified by Eris S. Raymong:
“The organization of the software and the organization of the software team will be congruent; commonly stated as ‘if you have four groups working on a compiler, you’ll get a 4-pass compiler.’”
Organizational Archetypes
- Functional-oriented organizations optimize for expertise, division of labor, or reducing cost. These organizations centralize expertise, which helps enable career growth and skill development, and often have tall hierarchical organizational structures.
- Market-oriented organizations optimize for responding quickly to customer needs. These organizations tend to be flat, composed of multiple, cross-functional disciplines .. which often lead to potential redundancies across the organization. (__most commonly seen in early adopters of devOps).
- Matrix-oriented organizations attempt to combine functional and market orientation. However, as many who work in or manage matrix organizations observe, matrix organizations often result in complicated organizational structures
Why Functional oriented organizations fail to adopt devOps?
.. as we increase the number of Development teams and their deployment and release frequencies, most functionally-oriented organizations will have difficulty keeping up and delivering satisfactory outcomes, especially when their work is being performed manually.
How to adopt Market organization practices? Instead of re-organizing, embed functional specialist into service teams or automate the specific process (like provisioning, testing). This will help service teams to deliver value independent of other groups.
Common Trend in good DevOps organizations
..a high-trust culture that enables all departments to work together effectively, where all work is transparently prioritized and there is sufficient slack in the system to allow high-priority work to be completed quickly.
Issue of monolithic application
When we have a tightly-coupled architecture, small changes can result in large scale failures. As a result, anyone working in one part of the system must constantly coordinate with anyone else working in another part of the system they may affect, including navigating complex and bureaucratic change management processes.
Bounded Contexts .. described in Domain Driven Design by Eric J. Evans
The idea is that developers should be able to understand and update the code of a service without knowing anything about the internals of its peer services. Services interact with their peers strictly through APIs and thus don’t share data structures, database schemata, or other internal representations of objects.
Heather Mickman - Requirements from team members
Because our team also needed to deliver capabilities in days, not months, I needed a team who could do the work, not give it to contractors—we wanted people with kickass engineering skills, not people who knew how to manage contracts.
Building the foundation
One of the recurring idea in building the foundation is for Operations team to build self-service capabilities for the Dev teams. Basically, Dev teams should rely on Ops tools rather than on Ops people. The tools should be completely automated and the usage should be on “on demand” basis. Dev teams should not have to use ticketing system or it’ll lead to bottle necks.
Breaking the Dev / Ops boundaries It is better to either:
- embed Ops engineers into Dev teams OR
- assign Ops liason to Dev teams
This will ensure that Ops priorities are now driven by the goals of the product teams as opposed to Ops focused inwardly on solving their own problems. It has a side-effect where the interaction can help the dev teams understand the process and open up automation opportunities.
Scrum Standup meetings
Popular ritual of Scrum is the Daily Standup meeting. Discuss:
- what was done yesterday
- what is going to be done today
- what is preventing you from getting your work done
Retrospectives

An agile practice where teams meet at the end of a development interval and discuss 3 things:
- what was successful
- what can be improved
- how to incorporate the success and improvements in the future iterations
Building Kanbans for Operations
Making the work of ops visible ensures that it is easier to keep track of the work in progress, the effort required to move the code to production and the points where back-logs occur and potentially improve the process.
The First Way - Practices of Flow
my summary To help in a fast deployments, the basic building blocks are:
- create the foundation for an automated deployment pipeline
- automate testing
- trunk based development
- enable low-risk releases and very find-grained telemetry
In Puppet Labs’ 2014 _State of DevOps Report the use of version control by Ops was the highest predictor of both IT performance and organizational performance. In fact, whether Ops used version control was a higher predictor for both IT performance and organizational performance than whether Dev used version control.
Why is this so? It’s because there are a lot more complex details involved in configurable settings than in the application code.
Easier to build and throw-away infrastructure
Bill Baker, a distinguished engineer at Microsoft, quipped that we used to treat servers like pets: “You name them and when they get sick, you nurse them back to health. [Now] servers are [treated] like cattle. You number them and when they get sick, you shoot them.”
What is done? “Done” should be re-defined to “running in production-like” environment. Get away from a feature being called done when it runs on a developer machine.
Fast & Reliable Automated testing
Warning bells to IT outsourcing companies specializing in just testing services?
we are likely to get undesired outcomes if we find and fix errors in a separate test phase, executed by a separate QA department only after all development has been completed.
_Automated testing process __ _my summary Automated testing ensured quality is built at the earliest stage into the product. By having automated unit tests, errors are found at an earlier stage and avoids re-work. Even when a bug is found at a later stage, the remedial process should be to constructed an equivalent unit test to catch a similar bug. Logging of the tests and its results automatically collects evidence for audit and compliance requirements. Integration tests tend to be brittle and it is always better to find as many bugs during unit and acceptance testing.
Refer to the excellent blog post by Martin Fowler titled Test Pyramid.
 Goal of Deployment Pipeline
Goal of Deployment Pipeline
The goal of the deployment pipeline is to provide everyone in the value stream, especially developers, the fastest possible feedback that a change has taken us out of a deployable state.
When we use infrastructure as code configuration management tools, we can use the same testing framework that we use to test our code to also test that our environments are configured and operating correctly.
Enable and Practice Continuous Integration
Trunk based development (my summary) The more time developers work on a branch, the more difficult it is to merge back. Since it is hard to merge, we tend to delay and this leads to self-defeating cycle.
Without automated testing, continuous integration is the fastest way to get a big pile of junk that never compiles or runs correctly.
- Gary Gruver
** Version control & Continuous Integration ** ..after comprehensive use of version control, continuous integration is one of the most critical practices that enable the fast flow of work in our value stream, enabling many development teams to independently develop, test, and deliver value.
Gated Commits: Basically, verifying the code before it is merged into trunk. When a developer commits code, it undergoes the automated testing and only if it passes, code is merged into trunk. If it fails, the developer is notified and the merge fails. This ensures that the trunk is always tested code.
trunk-based development predicts higher throughput and better stability, and even higher job satisfaction and lower rates of burnout
- State of DevOps, 2015
Automate and enable low-risk releases
Automated deployments: Document the steps in deployment process and automate as much as possible.
3 characteristics of automated deployments
- Deploying the same way to every environment: By using the same steps for deployment in each environment, the process is tested and stable.
- Smoke testing our deployments: All the components should and critical transactions should be tested to ensure all components are tested.
- Ensure we maintain consistent environment: Ensure that the environments are synchronized.
Decouple release from deployment
- Deployment is the installation of a specified version of software to a given environment .. a deployment may or may not be associated with a release of a feature to customers.
- Release is when we make a feature (or set of features) available to all our customers or a segment of customers
Release Patterns
2 broad ways of release pattern:
- Environment-based release patterns
- Blue / Green
- Canary deployments: Typical deployment pattern:
- A1 group: In prod, but serve to internal users only
- A2 group: small % of customers
- A3 group: Rest of production servers
- Application-based release patterns
- Feature flag
- Dark launches
Cluster immune system extends on canary release by linking production monitoring to releae process. It’ll automativally roll back change when user-performance issues are detected.
Feature toggle enables us to do the following:
- Roll back easily
- Gracefully degrade performance
- Increase our resilience through a service-oriented architecture
Testing tip
To ensure that we find errors in features wrapped in feature toggles, our automated acceptance tests should run with all feature toggles on.
Ultimate goal of CI/CD effort: .. deployments should be low-risk push-button events we can perform on demand.
Paradox of goals in IT Organizations:
reducing our overall complexity and increasing the productivity of all our development teams is rarely the goal of an individual project.
Replacing monolith
2 patterns:
- Strangler application pattern
- Branching by abstraction pattern by Paul Hammant
The Second Way
Secret of high performers
High performers used a disciplined approach to solving problems, using production telemetry to understand possible contributing factors to focus their problem solving, as opposed to lower performers who would blindly reboot servers.
Telemetry defined
an automated communications process by which measurements and other data are collected at remote points and are subsequently transmitted to receiving equipment for monitoring .. telemetry is what enables us to assemble our best understanding of reality and detect when our understanding of reality is incorrect.
In the world of devOps, monitoring is so important that monitoring systems need to be more available and scalable than the systems being monitored.
Culture of blame Typical metric used is mean time until declared innocent - how quickl can we convince everyone else that we didn’t cause the outage.
Information radiator
“Information radiator” is the generic term for any of a number of handwritten, drawn, printed or electronic displays which a team places in a highly visible location, so that all team members as well as passers-by can see the latest information at a glance: count of automated tests, velocity, incident reports, continuous integration status, and so on.
The goal of telemetry and monitoring is to reduce MTTR instead of trying to focus and reduce MTBF.

Alert fatigue is the single biggest problem we have right now.. We need to be more intelligent about our alerts or we’ll go insane.
Tools
- statsD
- Zookeeper
- Etcd
- Consul
- stats - mean, median, std deviaton, chi squared distribution, fast fourier transform