
Rate Limiting with Python

{kind=link}
As programmers, we come across a variety of APIs that have some restrictions. Rate Limiting is one such constraint that is implemented to ensure that the system offering the service can actually accept and process the requests. According to Wikipedia, Rate Limiting is a feature of computer networks which is used to
control the rate of requests sent or received by a network interface controller. It can be used to prevent DoS attacks[1] and limit web scraping.
Whenever rate limits are enforced, the limit are generally documented. For example, OpenWeatherMap’s pricing page has the following limits on the free tier:
- 60 calls / minute
- 1,000,000 calls / month
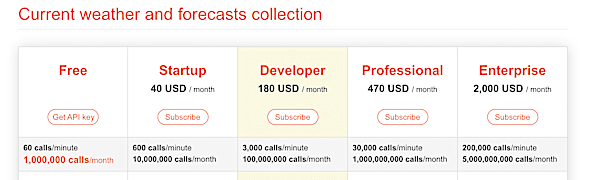
At 60 calls/minute, we could end up consuming the monthly quota in about 11.5 days. So the actual rate limit to remain within the monthly quota would be 1,000,000/ (30 days * 24 hours/day * 60 minutes/day) = 23 calls / minute. The question is how do you ensure that your code remain within this rate limit? Moreover, if you have multi-threaded program, you would need to ensure that the rate limit applies across the threads and the counter for request is thread-safe. Let’s take a look at this example. If you’d like to explore API rate limiting in details, please refer to this blog post.
Python Ratelimiter
One of the libraries that can help implement rate limits in Python is ratelimiter. The rate limiting functionality can be implemented using a few mechanisms as explained on the library page. In my case, I was interested in the decorater approach.
from ratelimiter import RateLimiter
@RateLimiter(max_calls=10, period=1)
def do_something():
pass
Until I came across this library, I had never used decorator. So I had to first understand that. If you are like me, head over to this wonderful article “Primer on Python Decorators” which explains the concept and use of decorators.
Test Drive Rate Limit
I wanted to take the library for a test drive. So I implemented a simple check. I would write a dummy server that just sent back some fixed string. The client code would make 60 requests but rate limited to 30 requests/minute.
Let’s give this a try.
Take 1: W/O Rate Limit
This code has no rate limiting. I wanted to check how long it would take to execute.
import requests
def access_rate_limited_api(count):
resp = requests.get('http://192.168.1.2:8000/knockknock')
print(f"{count}.{resp.text}")
for i in range(60):
access_rate_limited_api(i)
When I execute this code, it just makes a rapid series of calls and all 60 requests are executed within a few seconds.
Take 2: With Rate Limit
I tweaked the code and added the decorator to restrict the API to 30 calls/minute. I also added an additional decorator to indicate that the any function invocation that can’t succeed will go into sleep and should be retried.
import requests
from ratelimit import limits, RateLimitException, sleep_and_retry
ONE_MINUTE = 60
MAX_CALLS_PER_MINUTE = 30
@sleep_and_retry
@limits(calls=MAX_CALLS_PER_MINUTE, period=ONE_MINUTE)
def access_rate_limited_api(count):
resp = requests.get('http://192.168.1.2:8000/knockknock')
print(f"{count}.{resp.text}")
for i in range(60):
access_rate_limited_api(i)
When I invoke this method, requests numbered 0-29 (30 requests) are executed in one batch and the program halts. After a minute, it starts again and completes the next 30 requests. I can see this sleep in the access log as well. The timestamp jumps from 16:48:06 to 16:49:06.
192.168.1.4 - - [16/Aug/2021:16:48:06 -0700] "GET /knockknock HTTP/1.1" 200 12 "-" "python-requests/2.25.1"
192.168.1.4 - - [16/Aug/2021:16:48:06 -0700] "GET /knockknock HTTP/1.1" 200 12 "-" "python-requests/2.25.1"
...
192.168.1.4 - - [16/Aug/2021:16:49:06 -0700] "GET /knockknock HTTP/1.1" 200 12 "-" "python-requests/2.25.1"
192.168.1.4 - - [16/Aug/2021:16:49:06 -0700] "GET /knockknock HTTP/1.1" 200 12 "-" "python-requests/2.25.1
So clearly, rate limiting has occurred.
Take 3: Rate Limits with concurrency
Whenever network access is involved or a complex work-load is being written, we tend to use to multi-threaded approach. If you’d like to learn multi-threading with Python, the article “How To Use ThreadPoolExecutor in Python 3” is a good place to start.
Hence, my next issue was to implement rate limiting in a multi-threaded environment. I wanted to ensure that all the threads behave well and don’t exceed the 30 calls/min limit.
To verify this, I updated the code to add multi-threading. To keep it simple, I started with 3 threads. Using this, I call the same function as before.
import requests
from ratelimit import limits, RateLimitException, sleep_and_retry
from concurrent.futures import ThreadPoolExecutor as PoolExecutor
ONE_MINUTE = 60
MAX_CALLS_PER_MINUTE = 30
@sleep_and_retry
@limits(calls=MAX_CALLS_PER_MINUTE, period=ONE_MINUTE)
def access_rate_limited_api(count):
resp = requests.get('http://192.168.1.2:8000/knockknock')
print(f"{count}.{resp.text}")
with PoolExecutor(max_workers=3) as executor:
for _ in executor.map(access_rate_limited_api, range(60)):
pass
As before, in the access log, there were 30 requests within the same minute, a gap of 1 minute followed by the remaining 30 requests.
Putting it together
The example I have is a very simple use case. In my case, the final use-case was to ensure that I was within the rate limit for Cloudinary’s Admin API. In my case, the rate limit I was desiring was 3000 requests per hour. This translates to 50 requests minute. I was trying to extract information about a set of resources and print to a CSV file. By using the requests library with a concurrency of 5, I was able to achieve the desired throughput while remaining within the rate limits imposed by the API.