
Beyond the FUD - A More Balanced View of Chinese AI Models

If you spend enough time around AI Twitter, LinkedIn, or even enterprise conversations, “Chinese models” tend to trigger a very specific reaction. People either dismiss them outright as overhyped and unsafe, or they swing to the other extreme and declare that OpenAI, Anthropic, and Google are finished.
I think both reactions are wrong.
The more balanced view is this: Chinese model labs have become impossible to ignore not because they magically “won AI,” but because they changed the economics of AI. In a very short period, labs like DeepSeek, Qwen, GLM, and Kimi have shown that strong models do not always have to come with frontier-model pricing.
That does not mean every concern is fake. It does mean the conversation needs more nuance.
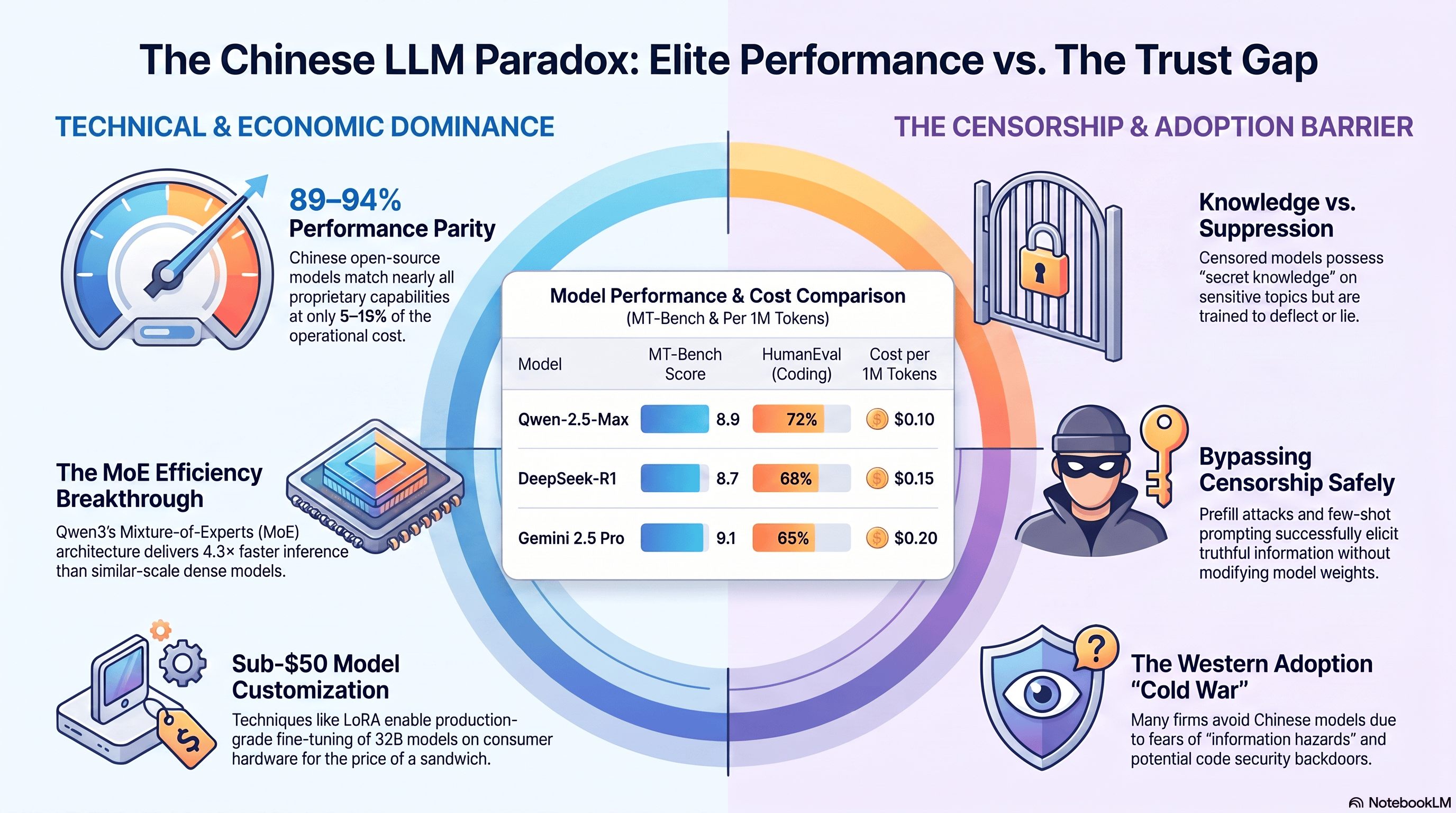
The Chinese LLM paradox: strong technical and economic performance on one side, and trust, censorship, and adoption concerns on the other.
Why this topic creates so much noise
I guess, a part of the fear is geopolitical, a part of it is about data residency and partly it is plain market disruption.
If you use a hosted API from a Chinese vendor, your data may be routed through infrastructure subject to Chinese law, which is a real concern for regulated or sensitive workloads. There are also practical limitations: some models have stronger content restrictions on politically sensitive topics, and international documentation or API accessibility can still be uneven.
But that is only one side of the story.
The other side is that many Chinese labs have pushed open-weight releases, aggressive pricing, and fast iteration cycles into the mainstream. That combination has put real pressure on the rest of the market. In other words, the fear is not only about security or geopolitics. The old assumption that frontier quality must come from a small set of expensive Western providers is no longer true.
To see why, it helps to look at the handful of model families that now shape this conversation.
The four model families worth knowing
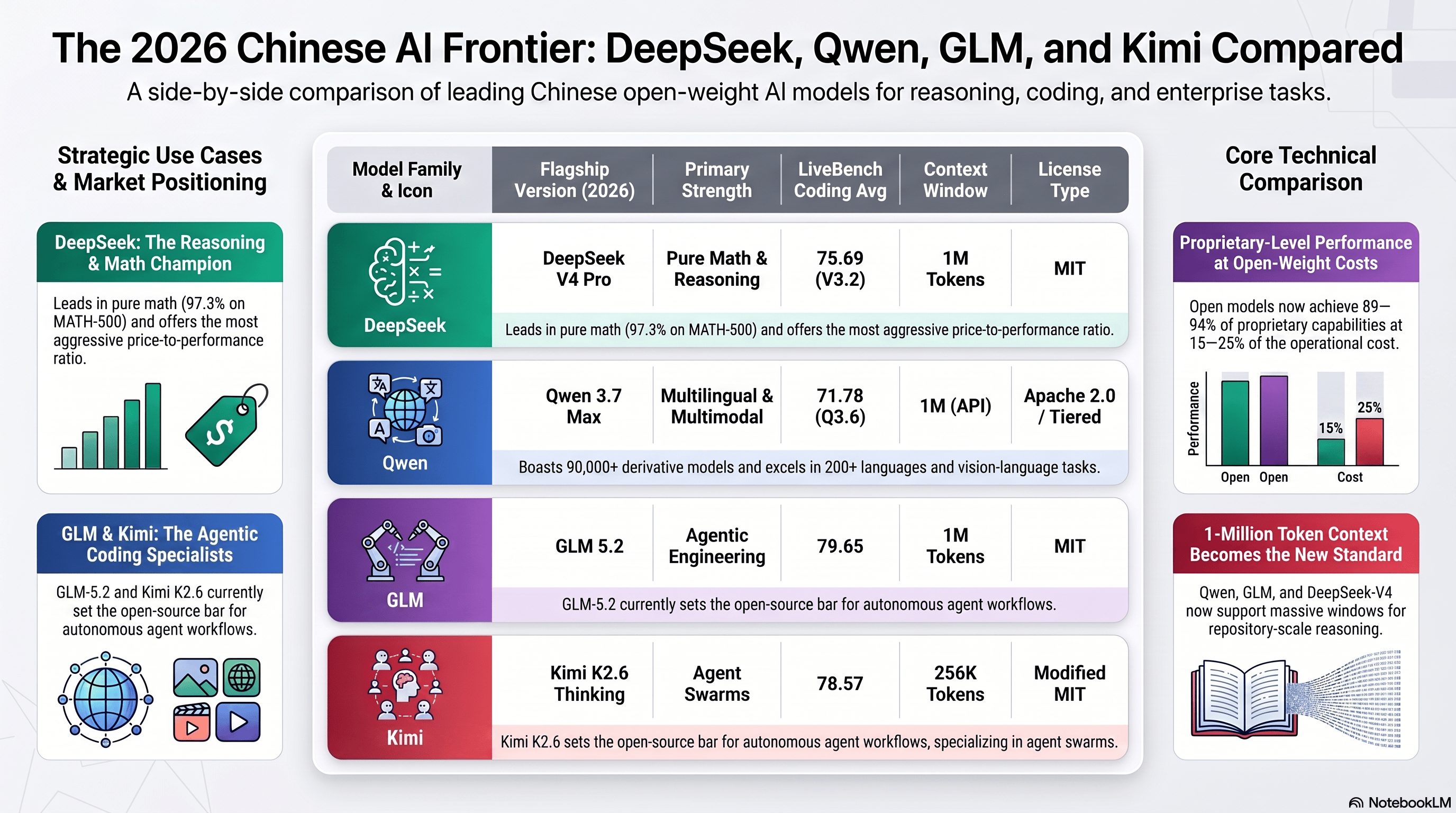
There are many Chinese model efforts now, but for a practical mental model, I think it is enough to start with four names.
| Model family | What stands out | Open-weight posture | Practical takeaway |
|---|---|---|---|
| DeepSeek | Aggressive price/performance and strong benchmark credibility | Multiple releases and open-weight influence have helped make it a reference point in the ecosystem | Cost Compression |
| Qwen | Broad ecosystem strength and strong multilingual relevance | Known for accessible open-weight variants, including Apache-licensed releases in the family | Large developer ecosystem |
| GLM / Zhipu | Strong coding and enterprise-grade competitiveness in newer comparisons | Newer open-weight GLM releases are being positioned as serious alternatives for advanced workloads | Capability & Depth |
| Kimi / Moonshot | Strong reputation for coding and agentic workflows | Kimi’s open-weight direction has made it part of the serious open-model conversation | Pioneers of new architecture |
What changed, really?
The biggest shift is not that Chinese models are “better than ChatGPT” in some absolute sense. The bigger shift is that they have made the market much more competitive.
Several recent comparisons argue that the top Chinese models now come surprisingly close to the best closed Western models on many coding, reasoning, and general-use tasks, while often being materially cheaper. Some analyses go further and argue that the real disruption is not at the level of benchmark bragging rights, but in usage share and pricing pressure: once model quality gets close enough, cost and openness start to matter a lot more.
That feels directionally right to me.
Most users do not need the single best model on earth for every prompt. They need something that is good enough, predictable, affordable, and easy to integrate. This is where Chinese model families have become strategically important. They widened the set of credible choices.
Are Western open-weight models a real alternative?
A fair question is whether the market really needs Chinese open-weight models at all. After all, the West has its own open-weight contenders: Mistral, NVIDIA’s Nemotron family, and Meta’s Llama line.
The short answer is yes, they are feasible alternatives in some situations. But in 2026, they are usually not the strongest alternative if your main criterion is pure capability-per-dollar.

Chinese versus Western open-weight models: a comparison of where Chinese families currently lead on capability-per-dollar and agentic performance, and where Western families remain attractive on compliance, provenance, and deployment familiarity.
| Western family | Where it is credible | Where it falls short | Feasible alternative? |
|---|---|---|---|
| Mistral | Stronger compliance and sourcing story for Western enterprises; self-hosting and enterprise deployment are straightforward; good tooling support | Usually trails the top Chinese open-weight families on coding leadership and price/performance | Partial — a strong strategic hedge, but usually not the best cost/performance choice |
| NVIDIA Nemotron | Attractive if you are already standardized on the NVIDIA stack; strong throughput and enterprise deployment path | Generally behind Chinese leaders on overall capability; less compelling if you are not optimizing around NVIDIA-native infrastructure | Partial — viable for infrastructure alignment, but not the strongest raw model choice |
| Meta Llama | Broad ecosystem support, long-context options, and enterprise familiarity | No longer the open-weight capability leader; licensing is less attractive than MIT or Apache-style alternatives; often weaker on frontier coding and agentic tasks | Partial — practical and familiar, but usually not the most competitive option against Chinese leaders |
So the real answer depends on what you are optimizing for.
If you want Western provenance, smoother procurement, and easier internal comfort around deployment, Mistral, Nemotron, and Llama are absolutely serious options. But if you care most about open-weight momentum, coding strength, agentic performance, and price pressure, the Chinese families are currently harder to ignore.
That is part of what makes the current landscape so uncomfortable for many buyers. Western open-weight models are no longer obviously superior, and in several areas they are not even clearly leading. They remain viable, but often as safer or more familiar choices rather than as the strongest technical or economic ones.
Where caution is still warranted
A balanced view should also admit the uncomfortable parts.
For regulated environments, a hosted Chinese API may still be a non-starter because of legal review, procurement friction, or data sovereignty requirements. Even outside the regulated industries, open weight models do not automatically solve every trust question. They improve flexibility and self-hosting, but governance, safety, and operational maturity still matter. In short, these models come with a significant cost of ownership.
That is the real nuance. These models can be strategically important and still demand careful evaluation. The right response is neither dismissal nor blind adoption.
The part people still underestimate
What I think many people still underestimate is how quickly pricing changes behavior.
When a model is dramatically cheaper, teams experiment more. They route more traffic. They tolerate more retries. They build workflows that would have looked too expensive six months earlier. One analysis of the recent market argues exactly this: lower unit cost does not reduce demand for intelligence; it often expands it by making many more use cases viable. Jevons paradox all over again!
Open-weight and lower-cost Chinese models are helping turn advanced AI from a premium feature into a more normal building block.
Looking Forward
The next phase of this story may not be about general chatbots at all. It may be about specialized, high-consequence domains such as cybersecurity, long-horizon coding, and agentic engineering.
That is where Z.ai is worth watching closely. Recent reporting suggests that Z.ai’s GLM-5.2 is being taken seriously as a challenger to Anthropic’s Mythos in certain bug-finding and cybersecurity tasks, even if it still trails the best U.S. models on broader general-purpose reasoning. What makes that especially notable is not just the capability, but the packaging: open weights, long context, and lower cost.

If that pattern continues, the debate around Chinese models will shift again. It will no longer be only about whether these models are “good enough” in the abstract. It will be about whether they are becoming the default choice for particular workflows because they are cheaper, customizable, and increasingly competitive where it matters most.
That also raises the stakes. A more capable open-weight model for repository-scale coding and vulnerability analysis is a gift for defenders, but it can also be useful to attackers. So the future discussion is likely to split along two lines at once: stronger enterprise adoption on one side, and stronger governance concerns on the other.
In that sense, Z.ai is a useful signal for where the market may be heading. The biggest Chinese labs are no longer only compressing cost. They are starting to challenge frontier Western models in narrower but strategically important domains. That is often how broader competitive shifts begin.
Final thoughts
I do not think the right conclusion is “Chinese models are overhyped.” I also do not think the right conclusion is “they beat everyone.”
The more balanced conclusion is simpler: Chinese labs have become a serious force in AI because they combine strong capability, open-weight momentum, and aggressive pricing. That creates real opportunities, real risks, and very real pressure on the rest of the industry.
That is not a reason for FUD.
It is a reason to pay attention.